
 3、学后训练:seaborn与数据可视化
3、学后训练:seaborn与数据可视化
seaborn本身是一个基于Matplotlib库的高级API封装包。
它提供了一种高度交互式界面, 集成了我们在数据分析中常用的图形, 通过seaborn的API可以快速的绘制出各种探索数据所用图形。
无需过多设置, 既可以绘制出很多精美, 实用的图形, 是一个非常值得学习的可视化模块。
在本课程中, 我们将seaborn的功能划分为五大模块:
分布 分类 关系 多图 回归
为什么要这样进行划分呢?
首先我们来思考一下, 在数据分析的过程中, 通过数据的可视化要达到什么样目的?
可视化最核心的目的, 是帮助我们快速, 直观的了解数据.
不同类型的数据类型,对可视化图形的选择,是不完全一样。
连续型数据的分布
对于连续型数据, 比如记录年龄、收入的字段,我们可以通过直方图和密度图快速了解数据在范围内的分布情况, 比如数据是集中还是分散? 偏态情况如何?有没有异常值等。 比如,以下是某城市在职职工月薪的直方分布图:
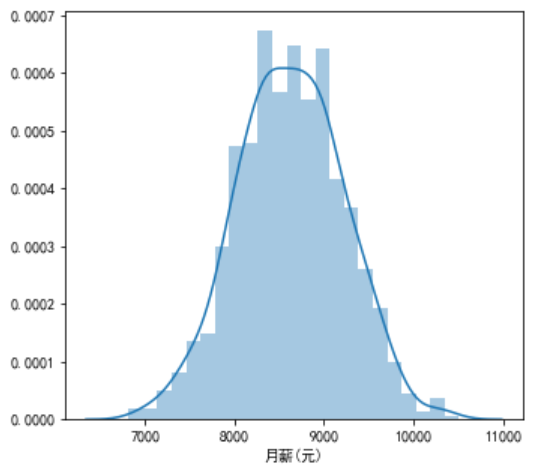
可见,该城市在职职工月薪集中在8500元左右。
离散型数据的分布
对于离散型数据, 比如问卷数据中,记录调查对象的性别、城市、婚否、所处行业类别的字段,我们可以简单的通过柱状图, 或者分类散点图查看离散型变量中每个类型出现的频次, 频率等。
比如,下图通过柱状图显示问卷数据中,调查对象所处行业的分布:
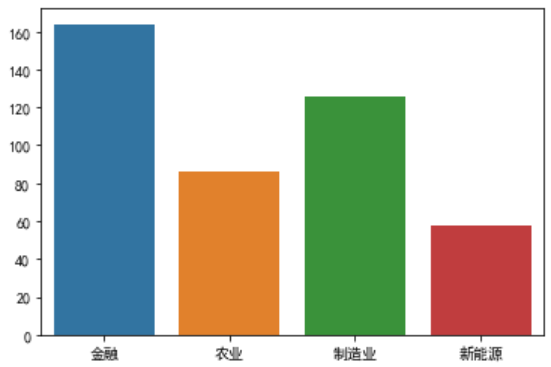
可以看到,从事金融业的人数是最多的。
两个连续变量之间的分布关系
单个变量探索完之后, 如果我们想要更进一步的探索两个变量之间的关系,可以通过关系型图形来查看,比如散点图、折线图等。
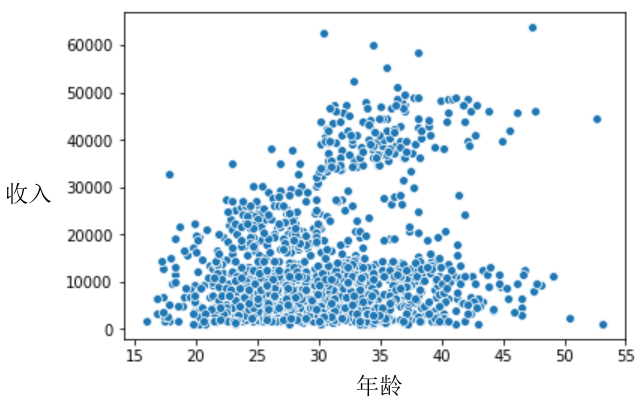
比如上面的散点图显示了某样本数据中收入和年龄两个变量的分布关系。
多图模块
当我们要可视化的变量比较多时, 一组一组的绘制未免麻烦,这时就可以通过seaborn中的多图模块, 批量地对多组变量进行绘制。
比如下面这幅图,显示了在机器学习经典的鸢尾花数据集中,花瓣长、花瓣宽、花萼长、花萼宽,这四个变量相互之间的关系。
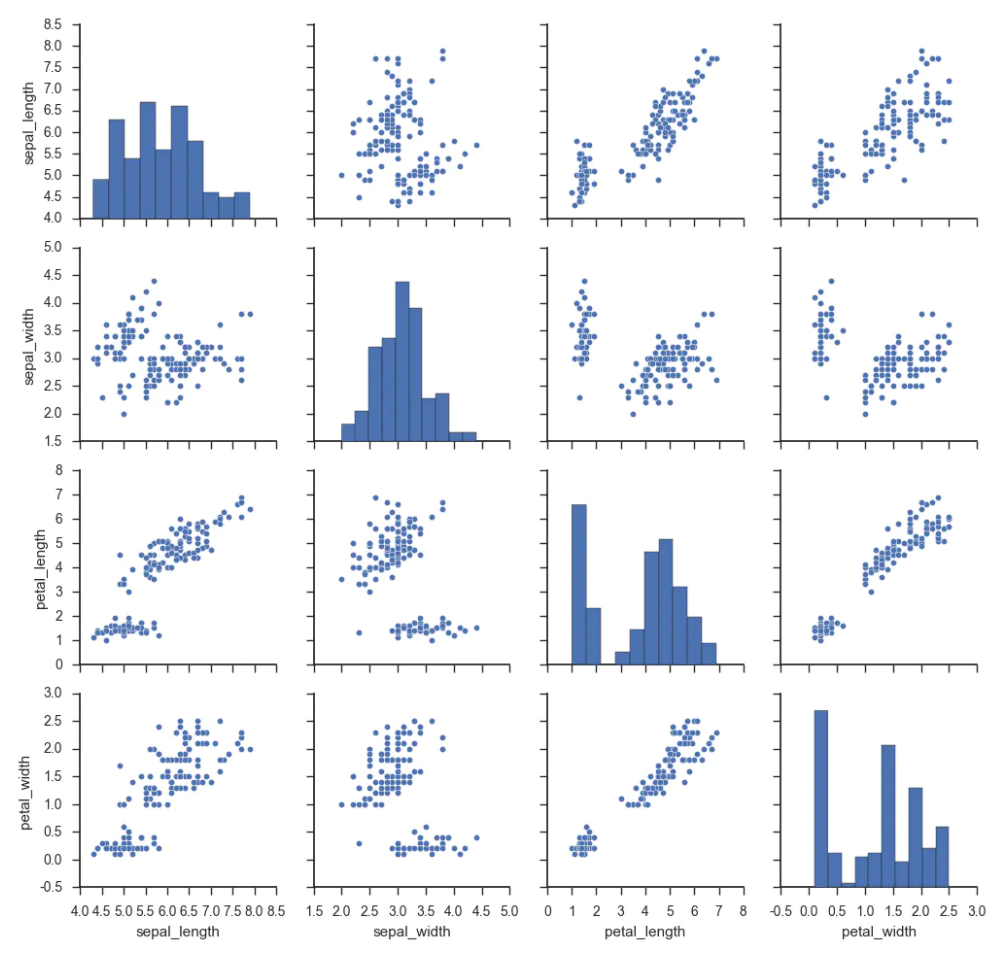
可见,一张图就能显示几个变量相互之间的关系,无疑是非常方便的,尤其是在快速查看变量多重共线性问题上。
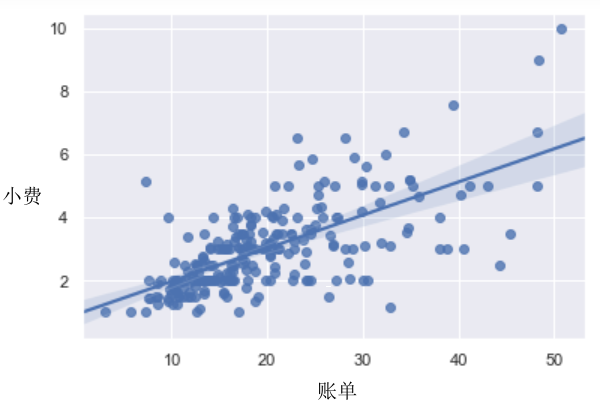
回归模块
构建回归模型时, 如果希望绘制出带有置信区间, 回归线或者残差图等特殊功能的图像,可以使用seaborn的回归模块图形。
比如,下图拟合了seaborn自带数据集tips中的账单总额和小费两个变量的回归关系。
尝试在右上角代码框输入以下代码:
import seaborn as sns
注:导入seaborn库时,一般使用简写sns
 findNaN.py
Ipython Shell
findNaN.py
Ipython Shell
