
反馈
 10、重复值处理
10、重复值处理
代码运行题
重复值处理
duplicated
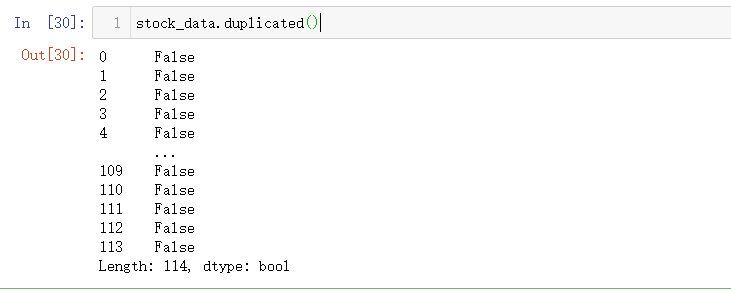
重复数据判断,第一次出现的情况均设置为False,所有其他情况均设置为True,返回bool值的Series
stock_data=pd.read_excel('/data/stock_data.xlsx')
stock_data.duplicated()
drop_duplicates将基于所有列删除重复的行
subset: 列名,可选,默认为None keep: {‘first’, ‘last’, False}, 默认值 ‘first’ first: 保留第一次出现的重复行,删除后面的重复行。 last: 删除重复项,除了最后一次出现。 False: 删除所有重复项。
inplace:布尔值,默认为False,是否直接在原数据上删除重复项或删除重复项后返回副本。(inplace=True表示直接在原来的DataFrame上删除重复项,而默认值False表示生成一个副本。)
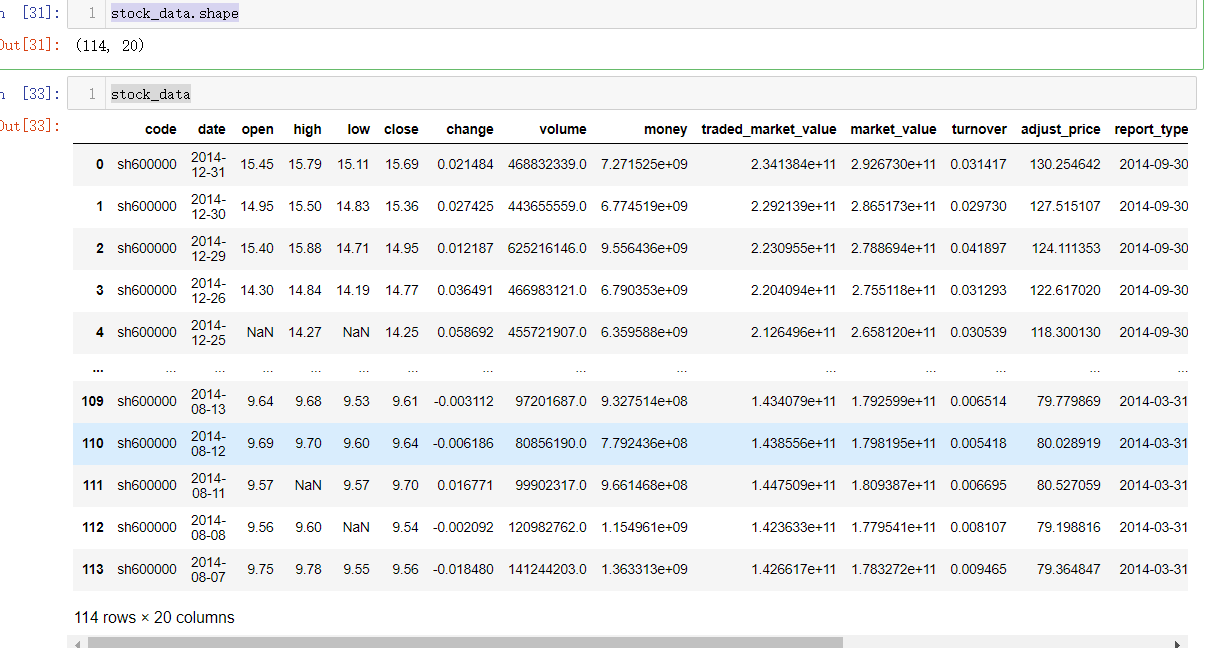
stock_data.shape
stock_data
stock_data.drop_duplicates()
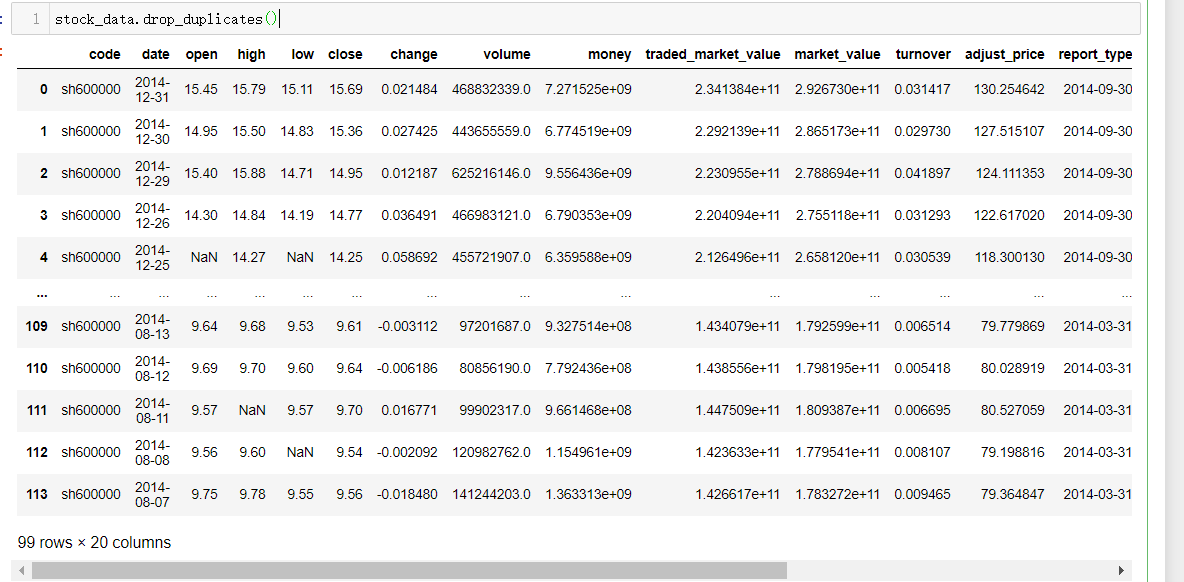
stock_data.drop_duplicates().shape
#删除特定列上的重复项,请使用subset
stock_data.drop_duplicates(subset="open")
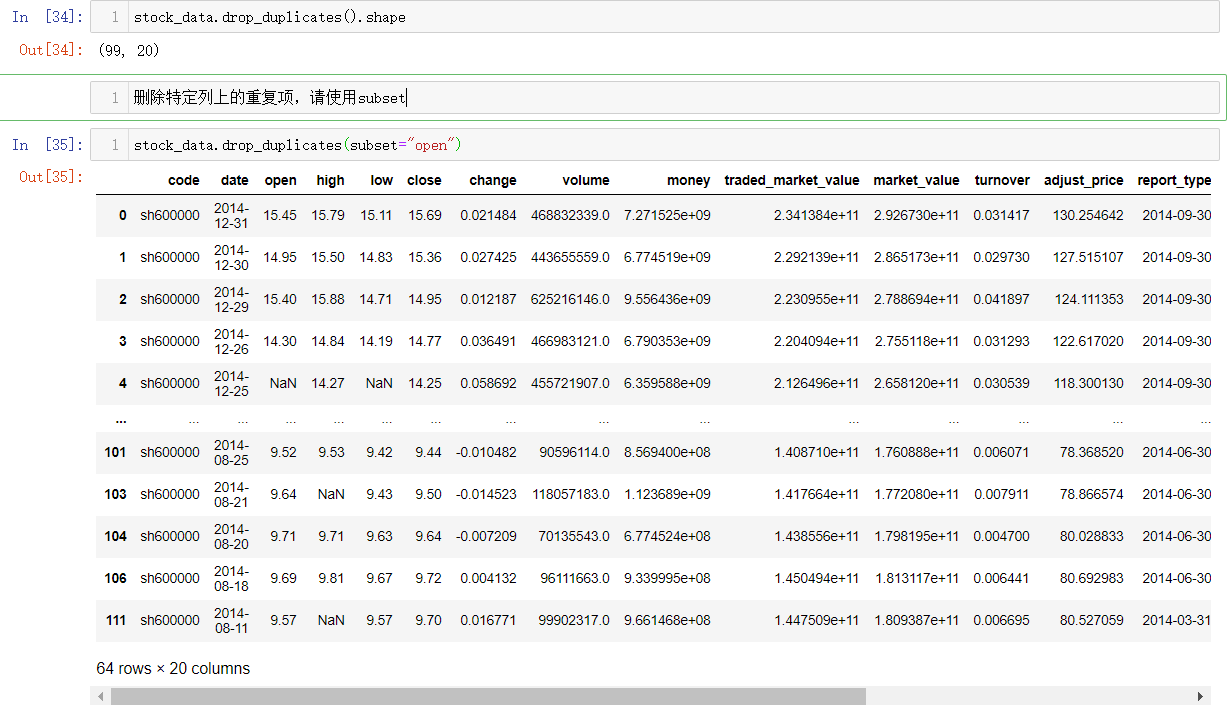
stock_data.drop_duplicates(subset="open").shape
#要删除重复的行并保留最后一次出现的值,请使用keep=‘last’
stock_data.drop_duplicates(subset=["open","close"],keep="last")
stock_data.drop_duplicates(subset=["open","close"],keep="last").shape
输出:(95, 20)
 findNaN.py
Ipython Shell
findNaN.py
Ipython Shell
