
反馈
 6、知识进阶: DataFrame分组后的操作
6、知识进阶: DataFrame分组后的操作
代码运行题
1. 分组后过滤filter()
如果分组之后,想要对小组数据聚合情况进行组筛选(将属于某类组的数据都删除),该怎么做?
这时,分组之后可以用filter()方法:
data=pd.read_excel("/data/Items_data.xlsx")
data.head()

data数据中每个商品生产地中商品的平均售价情况如下:
data.groupby("商品生产地")["售价"].mean()
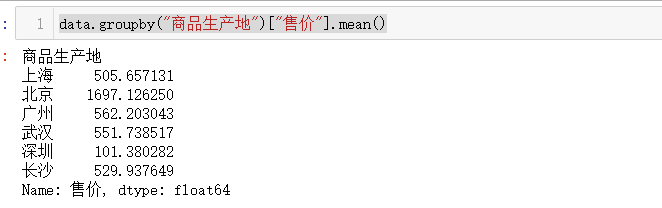
使用filter()方法,筛选出平均售价大于500的商品生产地,从上面的数据来看,就把深圳的数据过滤了
2. 分组后转换transform()
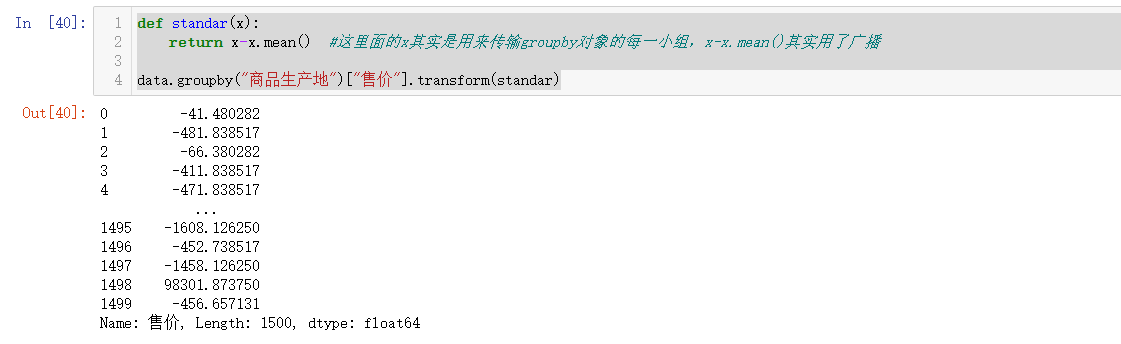
转换操作返回一个新的全量数据,数据转换之后的形状和原来的是一样的,常见的例子是实现数据标准化
如果我们想以商品生产地分组,对产品的售价进行组内标准化(每个产品的售价减去自己商品生产地的售价均值),可以尝试进行如下操作:
def standar(x):
return x-x.mean() #这里面的x其实是用来传输groupby对象的每一小组,x-x.mean()其实用了广播
data.groupby("商品生产地")["售价"].transform(standar)
3. 分组后应用apply()
如果你想在分组后对小组使用任意方法,可以使用apply()。
a. 输入一个分组数据的DataFrame进apply(),可以返回一个DataFrame或Series或一个标量。
b. group()和apply()的组合操作可以适应apply()返回的结果类型,因此非常灵活。
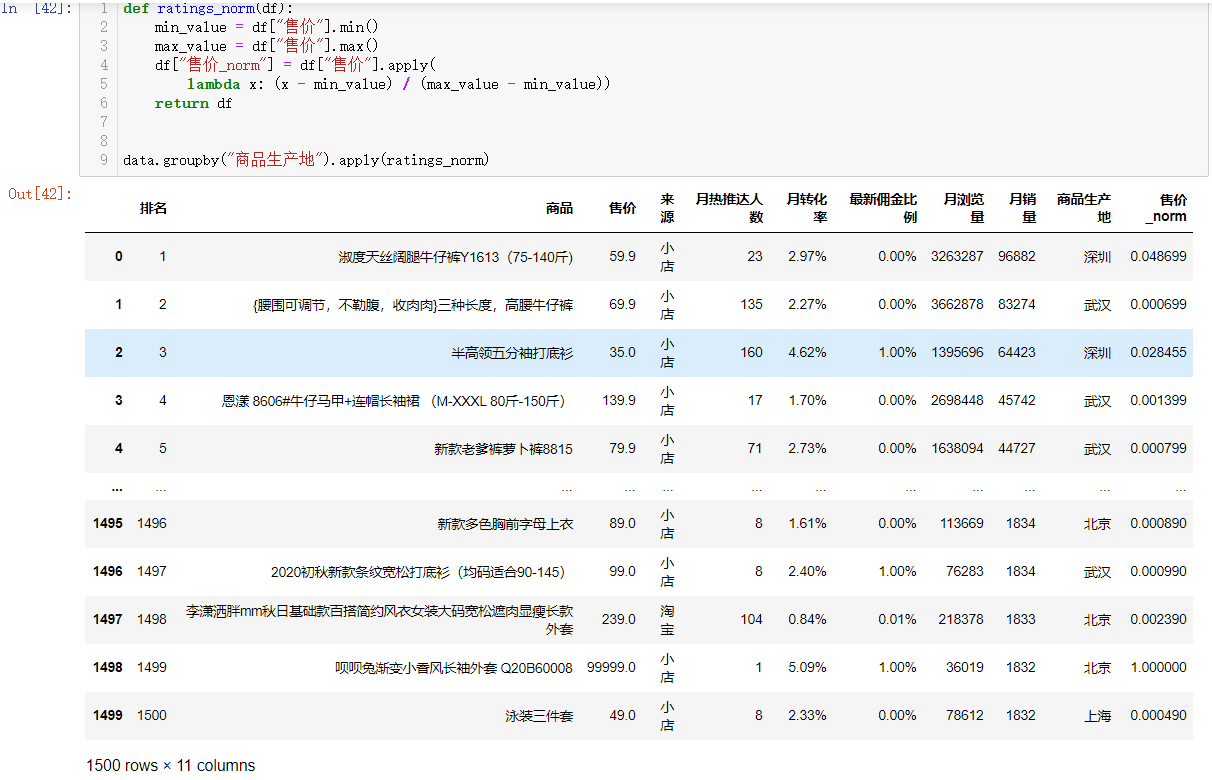
我们想对售价分组之后归一化(当前值减去最小值除以最大值减最小值的差)
def ratings_norm(df):
min_value = df["售价"].min()
max_value = df["售价"].max()
df["售价_norm"] = df["售价"].apply(
lambda x: (x - min_value) / (max_value - min_value))
return df
data.groupby("商品生产地").apply(ratings_norm)
 findNaN.py
Ipython Shell
findNaN.py
Ipython Shell
