
反馈
 4、缺失值处理:dropna
4、缺失值处理:dropna
代码运行题
dropna
既然有缺失值了,常见的一种处理办法就是丢弃缺失值。使用 dropna 方法可以丢弃缺失值。
user_info.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
Seriese 使用 dropna 比较简单,对于 DataFrame 来说,可以设置更多的参数。
axis 参数用于控制行或列,跟其他不一样的是,axis=0 (默认)表示操作行,axis=1 表示操作列。
how 参数可选的值为 any(默认) 或者 all。any 表示一行/列有任意元素为空时即丢弃,all 一行/列所有值都为空时才丢弃。
subset 参数表示删除时只考虑的索引或列名。
thresh参数的类型为整数,它的作用是,比如 thresh=3,会在一行/列中至少有3个非空值时将其保留,否则将这一整行/整列的数据删除。
直接对DataFrame对象使用.dropna()方法会删除掉所有带有缺失值的行(返回新表,并不是改变原表)。
stock_data = pd.read_excel('/data/stock_data.xlsx')
stock_data.dropna()

参数axis
如果里面增加axis参数,指定第二坐标轴,就会默认删掉出现缺失值的列
stock_data.dropna(axis=1)
df.dropna( )中的参数how和thresh是设置删除行列标准的参数:

参数how
how="all"只有当该列(或行)全都为缺失值时,才会将该列删除
stock_data.dropna(axis=1,how="all")
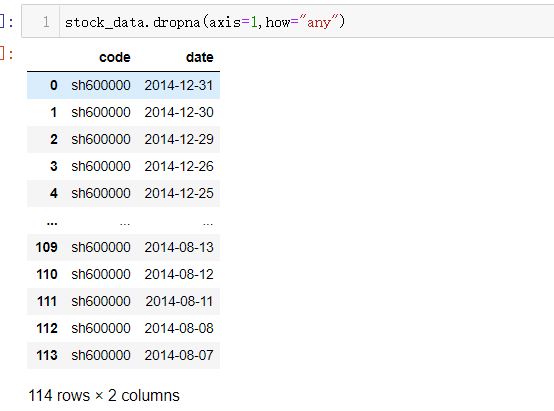
 how="any"只有当该列(或行)有一个缺失值,就会将该列删除
how="any"只有当该列(或行)有一个缺失值,就会将该列删除
stock_data.dropna(axis=1,how="any")
参数thresh
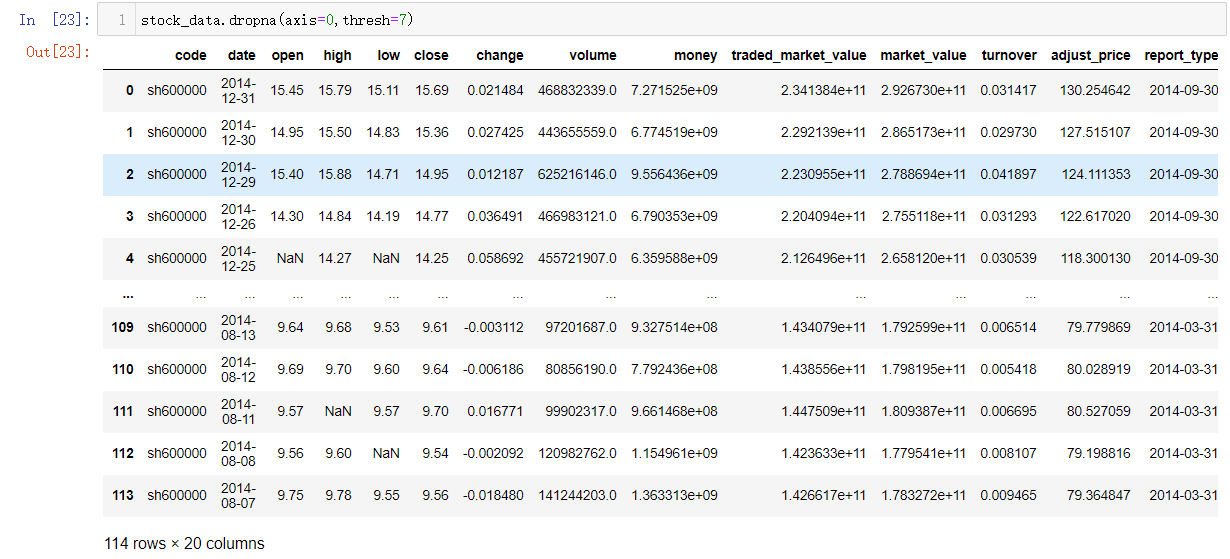
thresh参数设置的是:这一行/列除去NA值,剩余数值的数量大于等于你设置的值,便显示这一行/列,否则会被删除。
设置thresh=7,就是说,这一行/列中除掉缺失值,剩余的数值数量小于7,这行/列会被删掉。
stock_data.dropna(axis=0,thresh=7)
参数subset
subset设定一个子集,子集中的列作为剔除缺失值的参考列:
stock_data.dropna(axis=0,how = "any",subset = ["open","close"])

 findNaN.py
Ipython Shell
findNaN.py
Ipython Shell
