
反馈
 5、探索学习:KNN最优k的选取【交叉验证】
5、探索学习:KNN最优k的选取【交叉验证】
代码运行题
一、K折交叉验证
最常用的交叉验证是 K 折交叉验证。我们知道训练集和测试集的划分会干扰模型的结果,因此用交叉验证 K 次的结果求出的均值,是对模型效果的一个更好的度量。
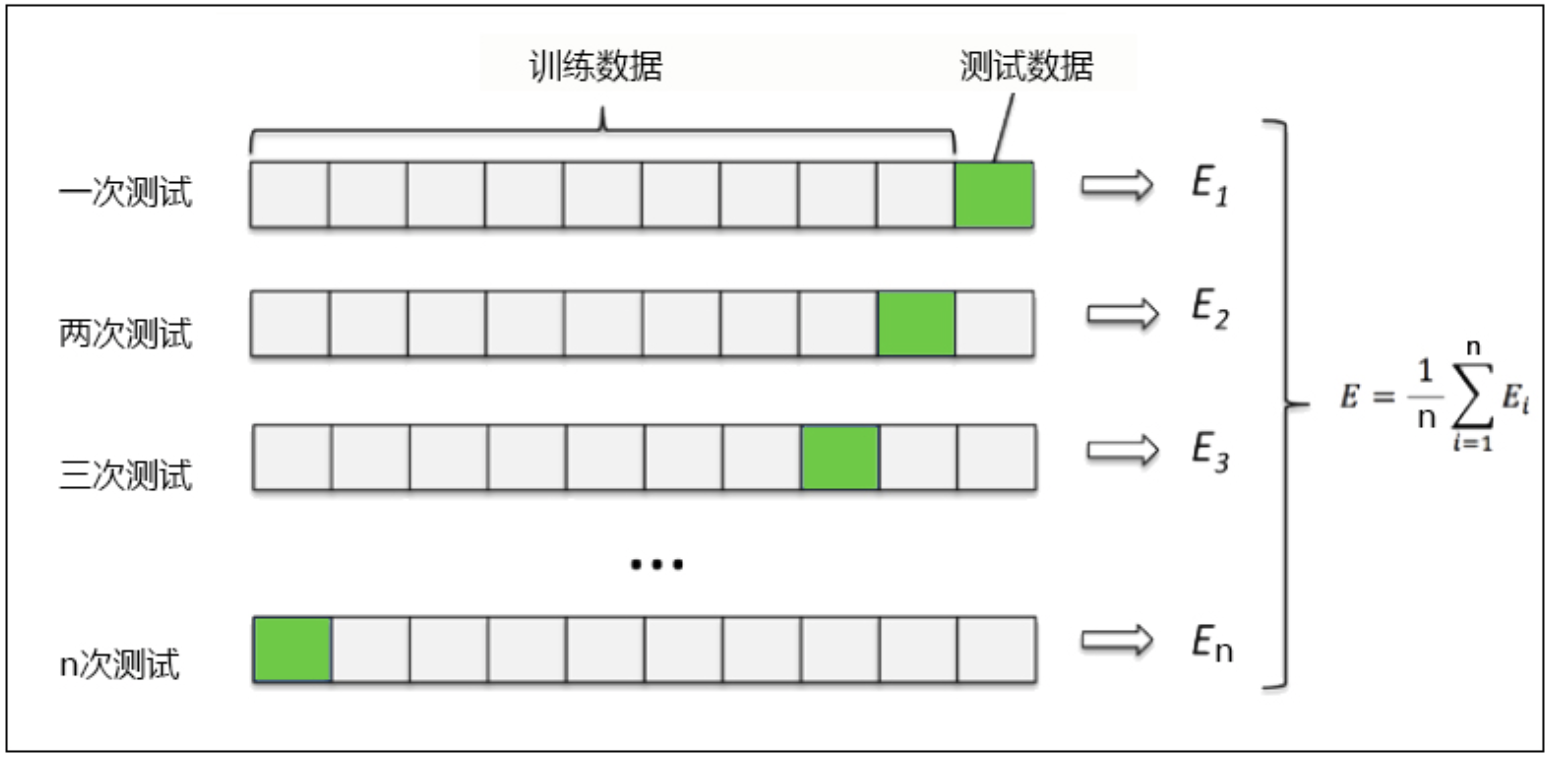
其中:是每次的模型评分。绿块表示的是测试数据,灰块表示的是训练数据。
图中直观地展示了K折交叉验证的整个过程:将数据集拆成了10个小块(9灰块+1绿块),这里每一小块作为一个数据子集,所以K=10,这是一个10折交叉验证的过程。
(1)第一次测试中:取倒数第一个子集(第一行中的绿块)作为测试数据,其余9块(第一行中的灰块)的子集作为训练数据,用来训练模型。并且得到第一次测试的模型评分。
(2)第二次测试中:取倒数第二个子集(第二行中的绿块)作为测试数据,其余9块(第二行中的灰块)的子集用来训练模型,得到第二次测试的模型评分。
(3)以此类推,直到把10个数据集用完,这样我们就会得到10个模型的评分,求10次评分的平均值即为交叉验证结果。
二、随机种子的问题 [补充]
思考: 确定了KNN算法的超参数之后,你会发现, 如果不固定随机数种子random_state的话, 每次运行的时候学习曲线都在变化,模型的效果时好时坏,这是为什么呢?
原因: 实际上,这是由于「训练集」和「测试集」的划分不同造成的。不设置随机种子的话,模型每次都会随机选取等比例的训练集和测试集,也就是说模型每次都使用不同的训练集进行训练,不同的测试集进行测试,自然也就会有不同的模型结果。
 findNaN.py
Ipython Shell
findNaN.py
Ipython Shell
