
反馈
 3、探索学习:KNN算法原理介绍
3、探索学习:KNN算法原理介绍
代码运行题
一、KNN算法原理
K最近邻算法,简称KNN(K-Nearst-Neighbor),英文意思就是K个最近的邻居。 KNN的算法原理非常简单:就是对于需要贴标签的数据样本(类比上节要预测的新红酒),KNN算法总是会先找k个和自己离得最近的样本,也就是找k个邻居的过程;再看看邻居的标签都属于哪种标签类型,根据 ”少数服从多数,一点算一票” 的原则进行判断;如果它的邻居中的大多数样本都是某一类样本,这个预测的样本就认为自己也是这一类样本。其中涉及到的原理是 “越相近越相似”,这也是KNN的基本假设。所以可以KNN算法的思路概括为:随大流。
划重点:
基本假设:“越相近越相似”
基本原则:"少数服从多数,一点算一票”
二、KNN算法描述
算法描述图见下:
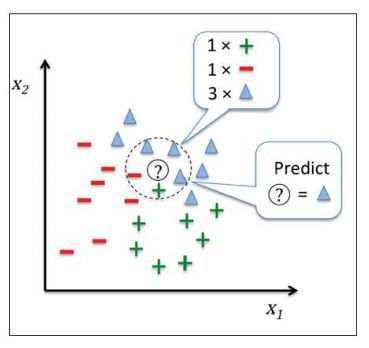 如图所示:预测数据点(图中的?)周围有一个绿+、一个红-、3个蓝△,利用KNN算法,根据少数服从多数的原则,这个数据点很有可能就是蓝△。在这个例子中邻居的个数k=5。
如图所示:预测数据点(图中的?)周围有一个绿+、一个红-、3个蓝△,利用KNN算法,根据少数服从多数的原则,这个数据点很有可能就是蓝△。在这个例子中邻居的个数k=5。
三、KNN算法执行流程
K-近邻算法就是通过距离来解决分类问题。整个算法结构如下:
(1) 确定:确定一个参数k,也就是要找几个最近邻点进行测试;
(2) 算距离:给定测试对象,计算所有其他样本点到我们测试样本点的距离;
(3) 找邻居:圈定距离测试点最近的k个样本点,作为测试对象的近邻;
(4) 做分类:对这k个样本点所属的类别投票,哪个类别多,就将该点预测成哪个类别。
根据本节内容尝试回答以下问题:
KNN算法最终是如何通过找到的K个近邻完成分类的?
 findNaN.py
Ipython Shell
findNaN.py
Ipython Shell
