
反馈
 7、探索学习:C4.5算法的改进(一)
7、探索学习:C4.5算法的改进(一)
代码运行题
一、连续型变量处理
在 算法中,还增加了对连续型变量的处理手段。如果输入的属性是连续型变量,则算法首先会对其按照从小到大的顺序进行排序,然后选取相邻的两个数的平均数作为切分数据集的备选点 ,若一个连续变量有个值,则在 算法的处理过程中将产生 个备选切分点,并且每个切分点都代表着一种二叉树的切分方案,过程如下:
注意: 此处对连续变量的处理并非是将其转化为一个拥有 个分类水平的分类变量,而是将其转化成了个二分方案 ,在接下来的节点划分过程中,这 个方案都可以单独参与划分属性的选择,也就是说,每一个切分方案都和一个离散变量的地位相同,不同的是,离散属性不可以再参与后面的子节点选择过程。
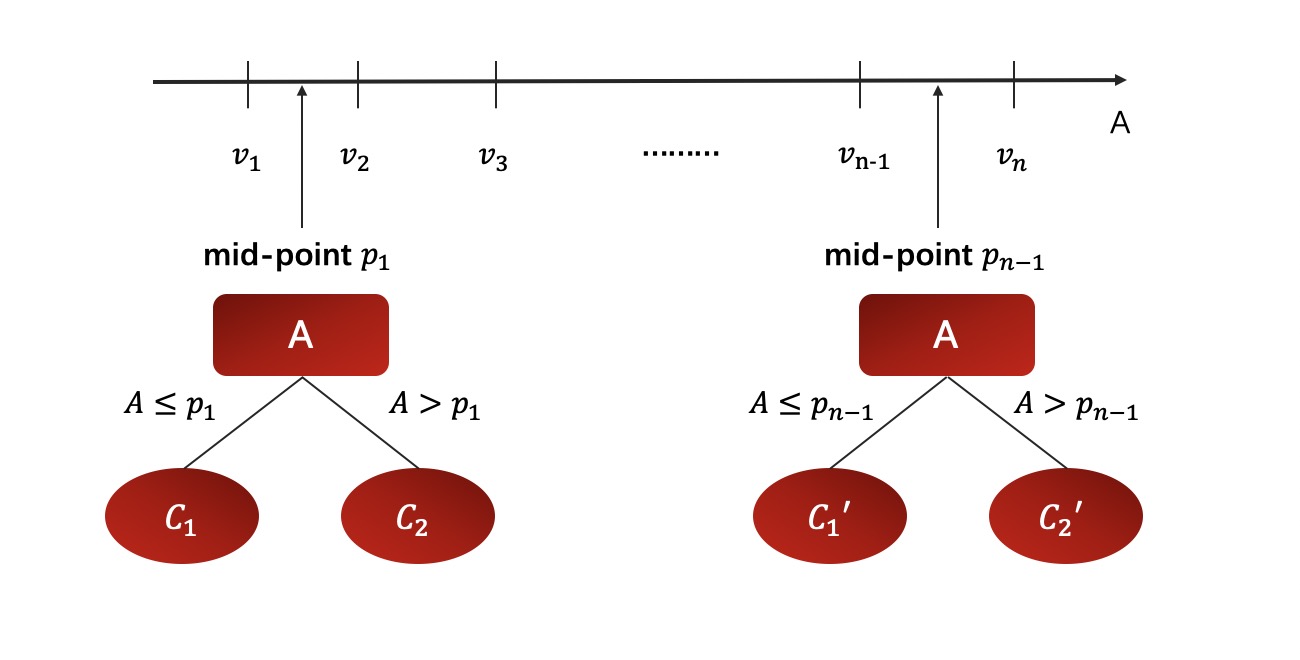
二、举例说明
例如,有如下数据集,数据集中只有两个字段,第一行代表年龄,第二行代表性别,由于年龄是连续型变量,所以在构建决策树的过程中需要对其进行离散化处理,具体切分方案如图所示。
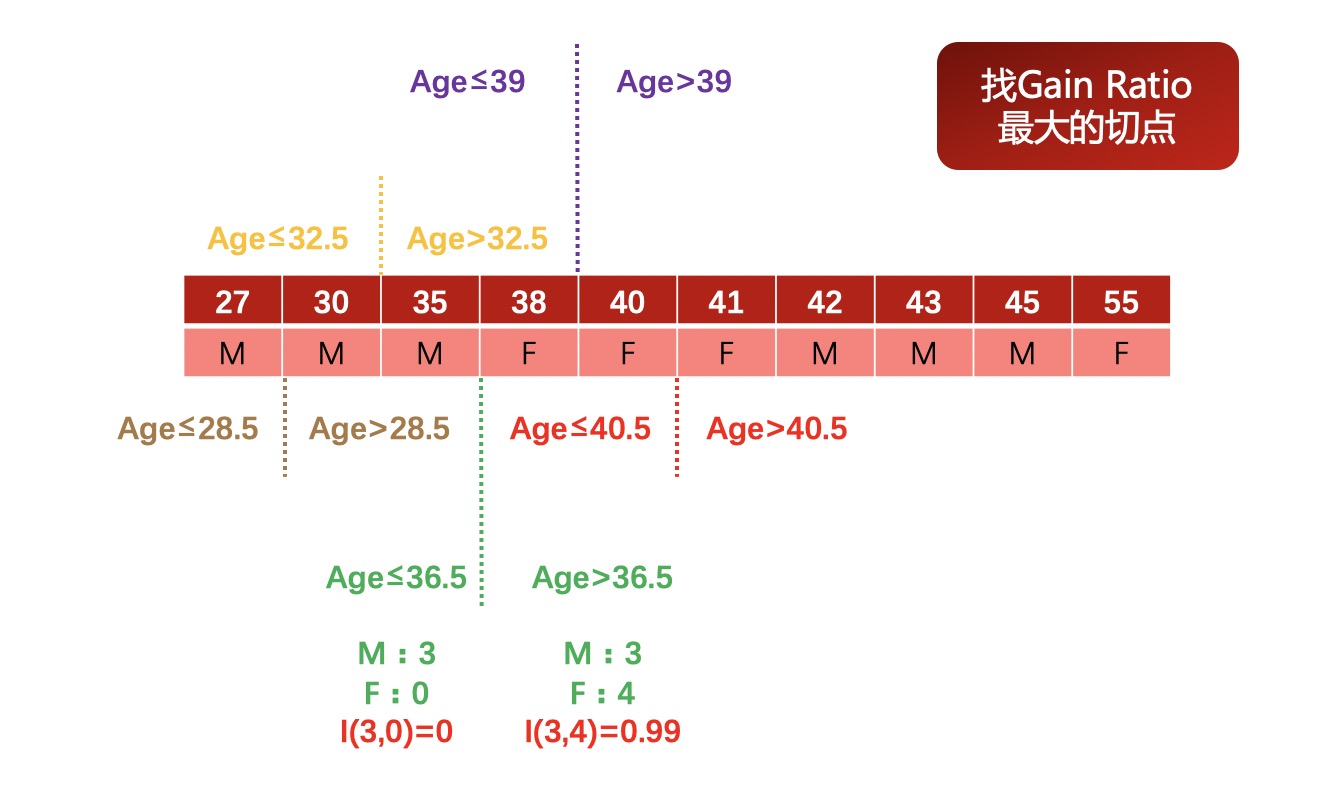

可以看出,对于包含连续型变量的数据集进行决策树构建的过程中需要消耗更多的运算资源。
拓展: 与此同时,我们也发现,当连续型变量的某中间点参与到决策树的二分过程中时,往往代表该点对于最终分类结果有较大影响,这也为我们连续变量的分箱压缩提供了指导性意见。例如上述案例,若要对Age列进行压缩,则可考虑使用36.5对其进行分箱,则分箱结果对于性别这一属性仍然具有较好的分类效果,这是决策树的最常见用途之一,也是最重要的模型指导分箱的方法。
 findNaN.py
Ipython Shell
findNaN.py
Ipython Shell
