
反馈
 4、探索学习:决策树的基本概念
4、探索学习:决策树的基本概念
代码运行题
一、决策树的概念
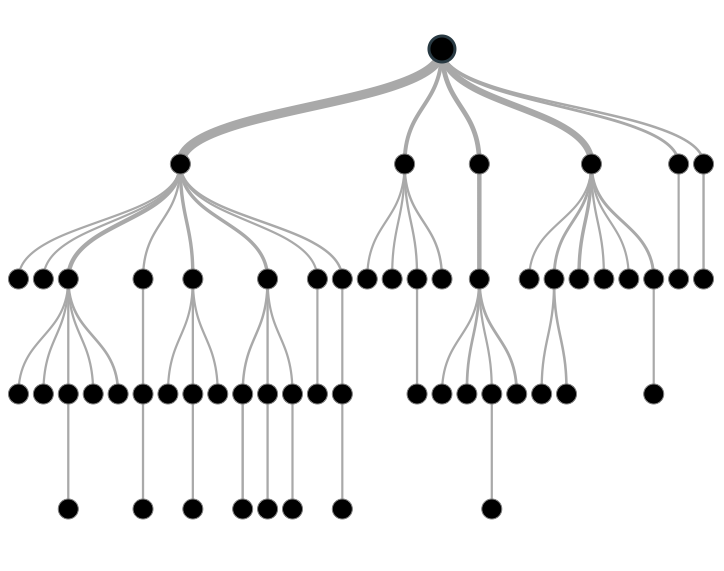
决策树是一种 有监督学习算法(也就是说,数据集的类别标签已存在),主要用于分类问题,输入变量和输出变量可以是离散值或连续值。决策树的基本思想是根据输入变量中最具区分性的变量,把数据集分割为两个或两个以上的子集合,如图所示:
二、分类决策树
分类决策树模型可以表示为基于特征对实例进行分类的树形结构(包括二叉树和多叉树)。模型采用贪婪思想进行分裂,即每次都选择可以得到最优分裂结果的属性进行分裂。
贪婪思想:也称为贪心算法,是指在对问题求解时,总是做出在当前看来的最好的选择。也就是说,不从整体最优上加以考虑,算法得到的是在某种意义上的局部最优解。
三、案例说明
我们用下面的例子来简要说明决策树在日常生活中的应用。
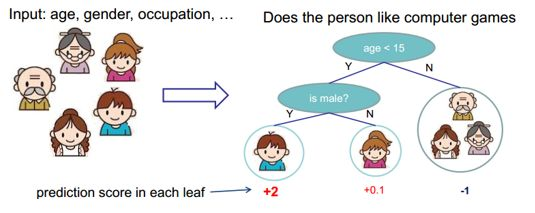
如图所示,给定样本数据集,输入的特征变量有性别、年龄、职业等。现在需要建立一个模型来预测谁更喜欢打游戏?那么,我们就需要考虑建立什么样的模型来达到更好的预测效果,此时,首先应该想到的就是决策树,因为它能够明确的找出一个人是否喜欢打游戏的属性依据,从而分离出喜欢打游戏的样本群体。
那么,思考一下,决策树是如何识别划分属性并进行样本数据分割的呢? 对于这个问题,决策树提供了很多种方法,我们将在后续学习中进行详细的介绍!
请根据本节内容回答以下问题:
决策为树进行分裂的算法思想是什么?
 findNaN.py
Ipython Shell
findNaN.py
Ipython Shell
