
反馈
 10 算法实操:轮廓系数的实现
10 算法实操:轮廓系数的实现
代码运行题
一、轮廓系数的代码实现
在 sklearn 中,使用模块 metrics 中的类 silhouette_score 来计算轮廓系数,它返回的是一个数据集中,所有样本的轮廓系数的均值。但我们还有同在 metrics 模块中的 silhouette_sample,它的参数与轮廓系数一致,但返回的是数据集中 每个样本自己的轮廓系数。
我们来看看轮廓系数在我们自建的数据集上表现如何:
二、尝试根据学习内容执行以下代码:
(1) 导入需要的模块、库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.metrics import silhouette_samples
plt.style.use('ggplot')
(2)自建数据集
#生成500*2的数据集,每一组数据可以有4个中心点,即数据集有4个标签
X, y = make_blobs(n_samples=500,
n_features=2,centers=4,random_state=1)
观察一下不同的 下,轮廓系数发生什么变化?
(3)计算轮廓系数
cluster = KMeans(n_clusters=3, random_state=0).fit(X)
silhouette_score(X,cluster_.labels_) #计算所有样本的轮廓系数均值。
silhouette_samples(X,cluster.labels_) #计算每个样本的轮廓系数。
输出为:
0.5150064498560357
array([ 0.62982017, 0.5034877 , 0.56148795, 0.84881844, 0.56034142,
0.78740319, 0.39254042, 0.4424015 , 0.48582704...])
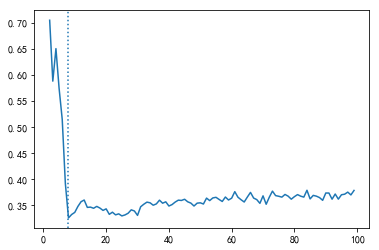
(4)轮廓系数随的变化图
score=[]
for i in range(2,100):
cluster= KMeans(n_clusters=i, random_state=0).fit(X)
score.append(silhouette_score(X,cluster.labels_))
plt.plot(range(2,100),score)
plt.axvline(pd.DataFrame(score).idxmin()[0]+2,ls=':') # x轴的取值起点是2,所以id+2
小节:
轮廓系数有很多优点:
(1) 它在有限空间中取值,使得我们对模型的聚类效果有一个“参考”。
(2) 它对数据的分布没有假设,因此在很多数据集上都表现良好。但它在每个簇的分割比较清洗时表现最好。
 findNaN.py
Ipython Shell
findNaN.py
Ipython Shell
