
反馈
 8、探索学习:评估指标【簇内误差平方和】
8、探索学习:评估指标【簇内误差平方和】
代码运行题
一、面试高危问题:如何衡量聚类算法的效果?
我们知道:聚类模型的结果不是某种标签输出,聚类的结果也是不确定的,其优劣由业务需求或者算法需求来决定,并且没有永远的正确答案。那我们如何衡量聚类的效果呢?
记得我们说过, KMeans 的目标是确保“簇内差异小,簇外差异大”,我们就可以通过衡量簇内差异来衡量聚类的效果。而Inertia 是用距离来衡量簇内差异的指标,因此,我们是否可以使用 Inertia 来作为聚类的衡量指标呢? Inertia 越小模型越好。 答案也是可以的,但是簇内误差平方和Inertia这个指标的缺点和极限太大。
二、关于簇内误差平方和Inertia的讨论
主要有以下几方面的情况:
(1)它不是有界的。我们只知道, Inertia 是越小越好,是 0 最好,但我们不知道,一个较小的Inertia 究竟有没有达到模型的极限,能否继续提高。
(2)它的计算太容易受到特征数目的影响,数据维度很大的时候, Inertia 的计算量会陷入维度诅咒之中,计算量会爆炸,不适合用来一次次评估模型。
(3)它会受到超参数 k 的影响,在我们之前的尝试中其实我们已经发现,随着 k 越大, Inertia 注定会越来越小,但这并不代表模型的效果越来越好了。
(4)Inertia 作为评估指标,会让聚类算法在一些细长簇,环形簇,或者不规则形状的流形时表现不佳:
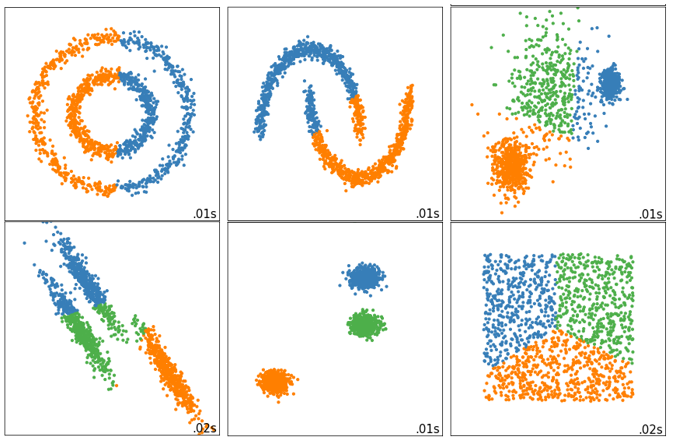
那我们可以使用什么指标呢? → 需要开启下节的学习
 findNaN.py
Ipython Shell
findNaN.py
Ipython Shell
