
反馈
 3、算法实操:Kmeans参数n_clusters
3、算法实操:Kmeans参数n_clusters
代码运行题
KMeans重要参数:n_clusters
参数n_clusters 是 KMeans 中的 ,表示我们告诉模型要分几类。这是 Kmeans 当中唯一一个必填的参数,默认为 8 类,但通常我们的聚类结果会是一个小于 8 的结果。通常,在开始聚类之前,并不知道n_clusters 究竟是多少,因此我们要对它进行探索。
当拿到一个数据集,如果可能的话,希望能够通过绘图先观察一下这个数据集的数据分布,以此为聚类时输入的 n_clusters 做一个参考。
尝试在代码框执行以下代码:
首先,我们来自己创建一个数据集。这样的数据集是我们自己创建,所以是有标签的。
(1)导入需要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
plt.style.use('ggplot')
(2)自建数据集
#生成500*2的数据集,每一组数据可以有4个中心点,即数据集有4个标签
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
plt.scatter(X[:, 0], X[:, 1], marker='o' ,s=8 )
plt.show()
输出为:
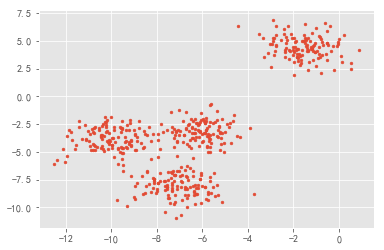
如果我们想要看见这个点的分布,怎么办?
color = ["red","pink","orange","gray"]
for i in range(4):
plt.scatter(X[y==i, 0], X[y==i, 1]
,marker='o' #点的形状
,s=8 #点的大小
,c=color[i]
)
plt.show();
输出为:
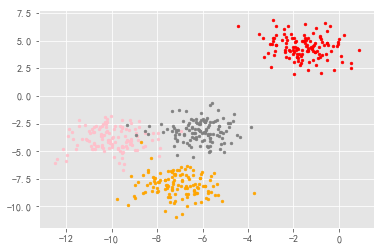 基于这个分布,我们来使用 Kmeans 进行聚类。这时,我们可以尝试猜测一下,这个数据中有几簇。
基于这个分布,我们来使用 Kmeans 进行聚类。这时,我们可以尝试猜测一下,这个数据中有几簇。
 findNaN.py
Ipython Shell
findNaN.py
Ipython Shell
