
反馈
 11 探索学习:KMeans算法流程
11 探索学习:KMeans算法流程
代码运行题
一、KMeans算法原理
KMeans算法作为聚类算法的典型代表,那它是怎么完成聚类的呢?
在 KMeans 算法中, 簇的个数用k表示,k是一个超参数,需要我们人为输入来确定。 Kmeans 的核心任务就是根据我们设定好的 k ,找出 k个最优的质心,并将离这些质心最近的数据分别分配到这些质心代表的簇中去。
二、KMeans算法流程
(1)首先设置参数k, k的含义为将数据聚合成几类(这里取k=3);
(2)从数据当中,随机的选择三(k)个点,成为聚类初始中心点;(图中初始三个中心点用蓝色、红色和黄色标记)
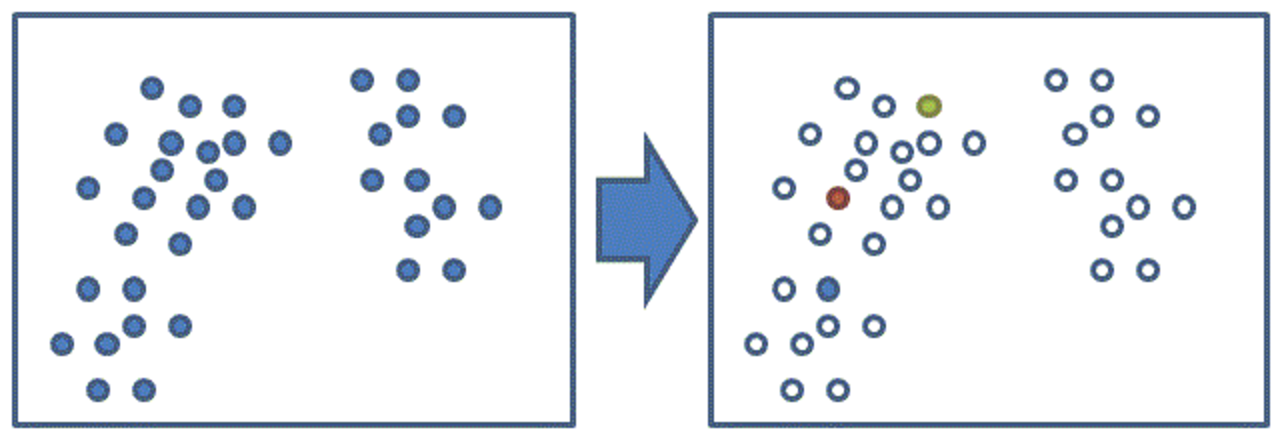
(3)计算所有其他点到这三(k)个点的距离, 然后找出离每个数据点最近的中心点, 将该点划分到这个中心点所代表的的簇当中去。那么所有点都会被划分到三(k)个簇当中去。
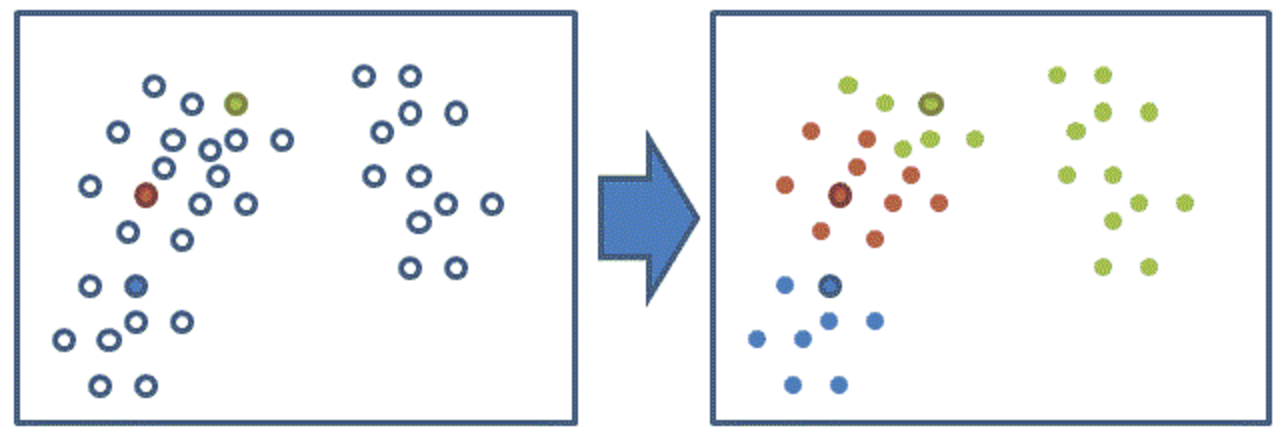
(4)重新计算三个簇的质心,作为下一次聚类的中心点;
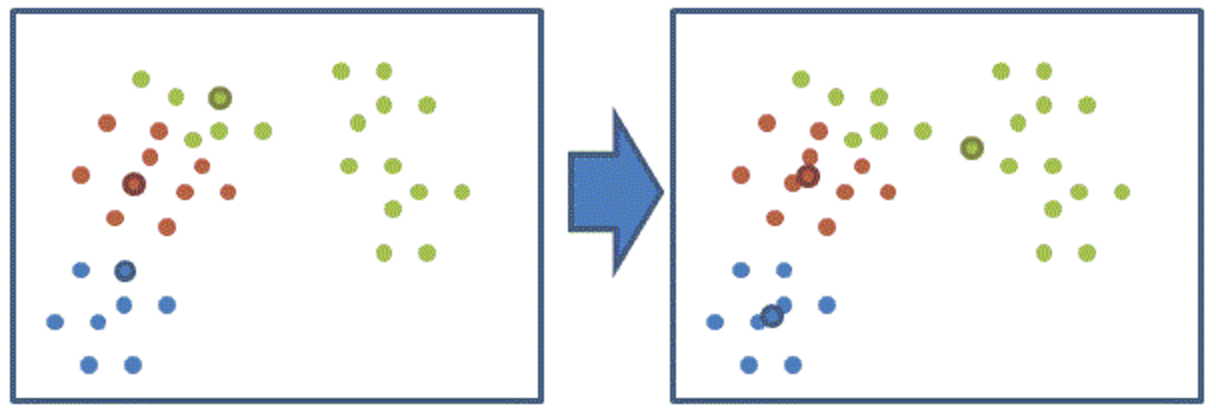
(5)重复上面的3-4步的过程,重新进行聚类,不断迭代重复这个过程。
(6)停止条件:
第一种:当重新聚类后,所有样本点归属类别都没有发生变化的时候。
第二种:当迭代次数达到规定的最大次数时,也会停止。
请根据学习内容回答以下问题:
(1) KNN和Kmeans算法原理中的相似之处是什么?
(2) Kmeans聚类的初始中心点是如何选择的?
 findNaN.py
Ipython Shell
findNaN.py
Ipython Shell
