
反馈
 9、探索学习:簇和质心的概念
9、探索学习:簇和质心的概念
代码运行题
一、什么是簇?
在前面的学习中,我们知道聚类就是让机器把数据集中的样本按照特征的性质分组,直观上来看,簇是一组一组聚集在一起的数据,在 一个簇 中的数据就认为是 同一类 ,簇就是聚类的结果表现。实际上簇并没有明确的定义,并且簇的划分没有客观标准,我们可以利用下图来理解什么是簇。该图显示了20个点和将它们划分成簇的3种不同方法,标记的形状(口、△、☆等)表示簇的隶属关系。
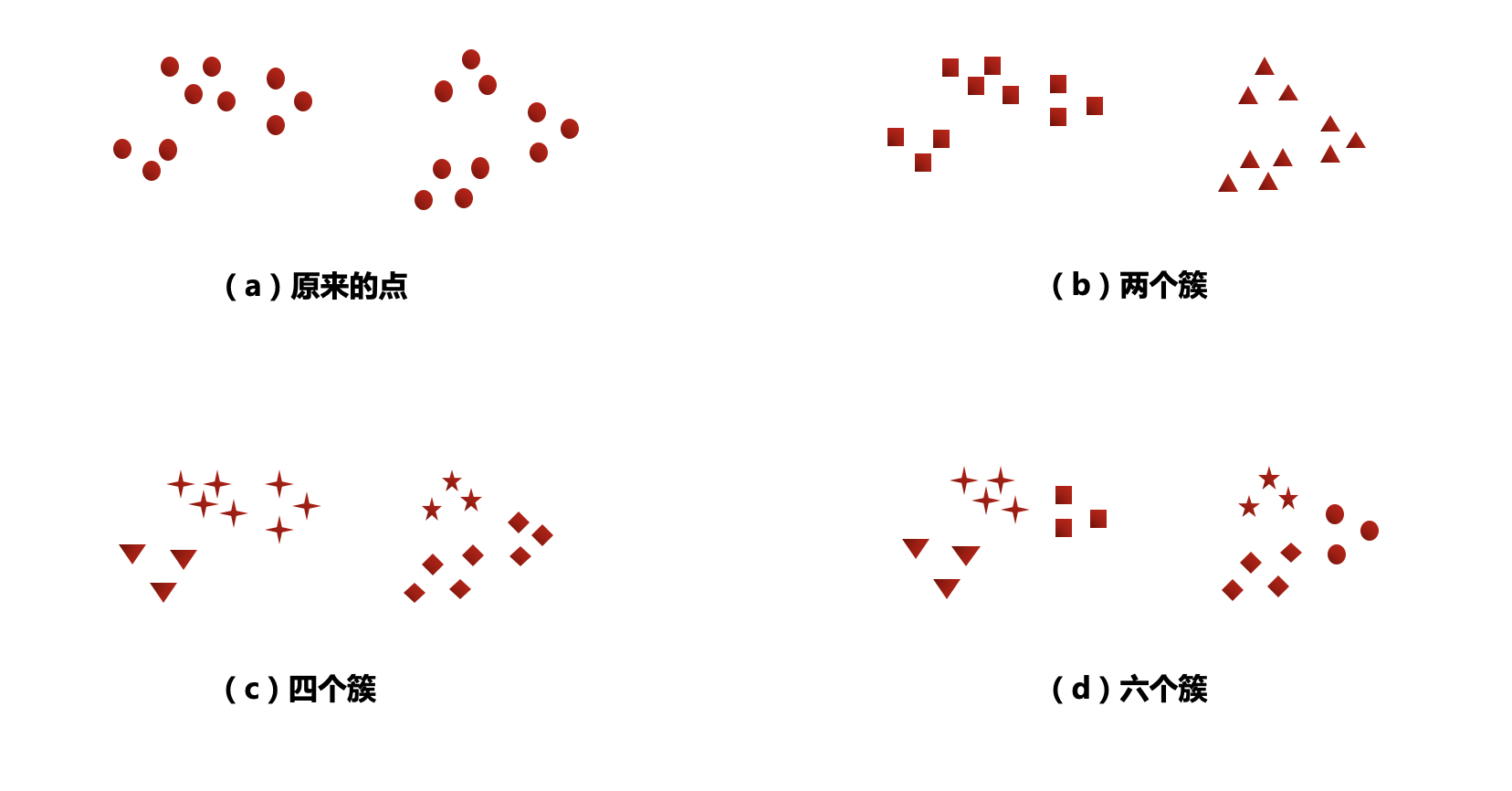
图中分别将数据划分成两个簇、四个簇和六个簇。直观地看,将图b的2个较大的簇再划分成4个簇好像也不无道理,这可能是人的视觉系统造成的假象。
该图表明簇的定义是不精确的,而最好的定义依赖于数据的特性和期望的结果。
二、什么是质心?
簇中所有 数据的均值 通常被称为这个 簇的“质心”( centroids) 。在一个二维平面中,一簇数据点的质心的横坐标就是这一簇数据点的横坐标的均值,质心的纵坐标就是这一簇数据点的纵坐标的均值。同理可推广至高维空间。
有了簇和质心的概念,下面理解KMeans算法就简单多了!
 findNaN.py
Ipython Shell
findNaN.py
Ipython Shell
