
反馈
 10 探索学习:KNN中距离讨论【数据归一化】
10 探索学习:KNN中距离讨论【数据归一化】
代码运行题
一、数据归一化的引入
什么是归一化呢?
同样基于乳腺癌数据集上观察X的数值概要,执行代码见下:
X_ = pd.DataFrame(X)
X_.head()
X_.describe().T
部分输出结果为:
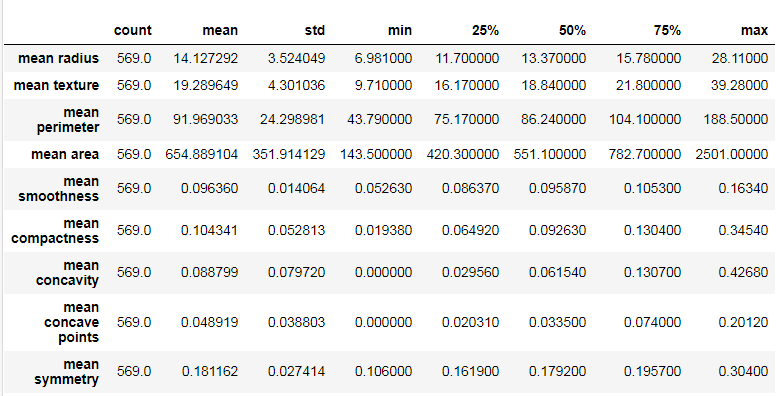
现象: 发现不同特征之间数值相差非常大;
原因: 是因为不同特征之间的度量量纲不同导致的。而在距离计算公式中, 是由数据之间的差值计算的, 因为量纲不同, 所以不同特征之间计算出的结果大小相差极大。
影响: 只有那些结果很大的才能对最终距离产生很大的影响, 数值小的几乎起不到什么作用, 这不是我们希望看到的。
这种现象在机器学习中被称为 "量纲不统一"。
二、数据归一化概念
当数据(x)按照最小值中心化后,再按极差(最大值-最小值)缩放,数据移动了最小值个单位,并且会被收敛到[0,1]之间,而这个过程,就称作数据归一化(Normalization,又称Min-Max Scaling)。
注意: Normalization是归一化,不是正则化,真正的正则化是regularization,不是数据预处理的一种手段。
0-1归一化的公式:
在sklearn当中,我们使用preprocessing.MinMaxScaler来实现这个功能。MinMaxScaler有一个重要参数,feature_range,控制我们希望把数据压缩到的范围,默认是[0,1]。
 findNaN.py
Ipython Shell
findNaN.py
Ipython Shell
