
 2、探索学习:微醺之时红酒鉴别
2、探索学习:微醺之时红酒鉴别
一、微醺之时:「赤霞珠」or「黑皮诺」
我们设想这样一个场景: 酒吧老板拿出十杯红酒,每杯略不相同,前五杯属于「赤霞珠」后五杯属于「黑皮诺」。然后老板又从酒柜中拿出一杯新的红酒,让你猜测这杯酒属于以上两类中的哪一个类别。
我们应该如何预测这杯酒的类别呢?
(1)数据集的构建:
俗话说:工欲善其事必先利其器,预测酒的类别,自然离不开必要的测量工具。首先我们用工具测量出每一杯酒的酒精浓度和颜色深度。再加上十杯酒各自的类别,就形成了这样一个数据集。如下图所示:
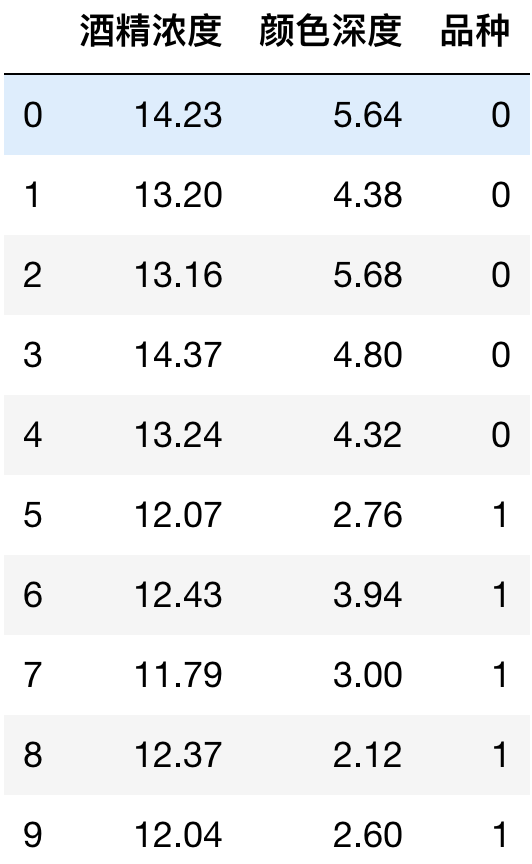
在这个数据集中,酒精浓度和颜色深度就是我们的特征feature,品种就是标签target。接下来我们要如何判断两杯酒之间是比较相似的呢?
【概念介绍】
A. 在上面的场景中,每一杯酒称作一个 「样本」,十杯酒组成一个样本集。
B. 酒精浓度、颜色深度等信息称作 「特征」。这十杯酒分布在一个 「 多维特征空间」 中。
C. 进入当前程序的“学习系统”的所有样本称作 「输入」,并组成 「输入空间」。在学习过程中,所产生的随机变量的取值,称作 「输出」,并组成 「输出空间」。
(2)数据可视化:
我们知道:同一个类别的酒,之所以是同一类别的,就是因为他们的工艺相似,口味也比较相似。换句话说,就是他们的特征相似,因此,如果我们能够找出新的这杯红酒和哪一个类别相似度更高,是不是就可以帮我们进行预测了呢?因为数据有两个特征, 我们可以将数据投影到一个二维空间当中去,赤霞珠用红色点标记,黑皮诺用紫色点标记。并且也将这杯新的酒也投影到空间中,用黄色点做标记。
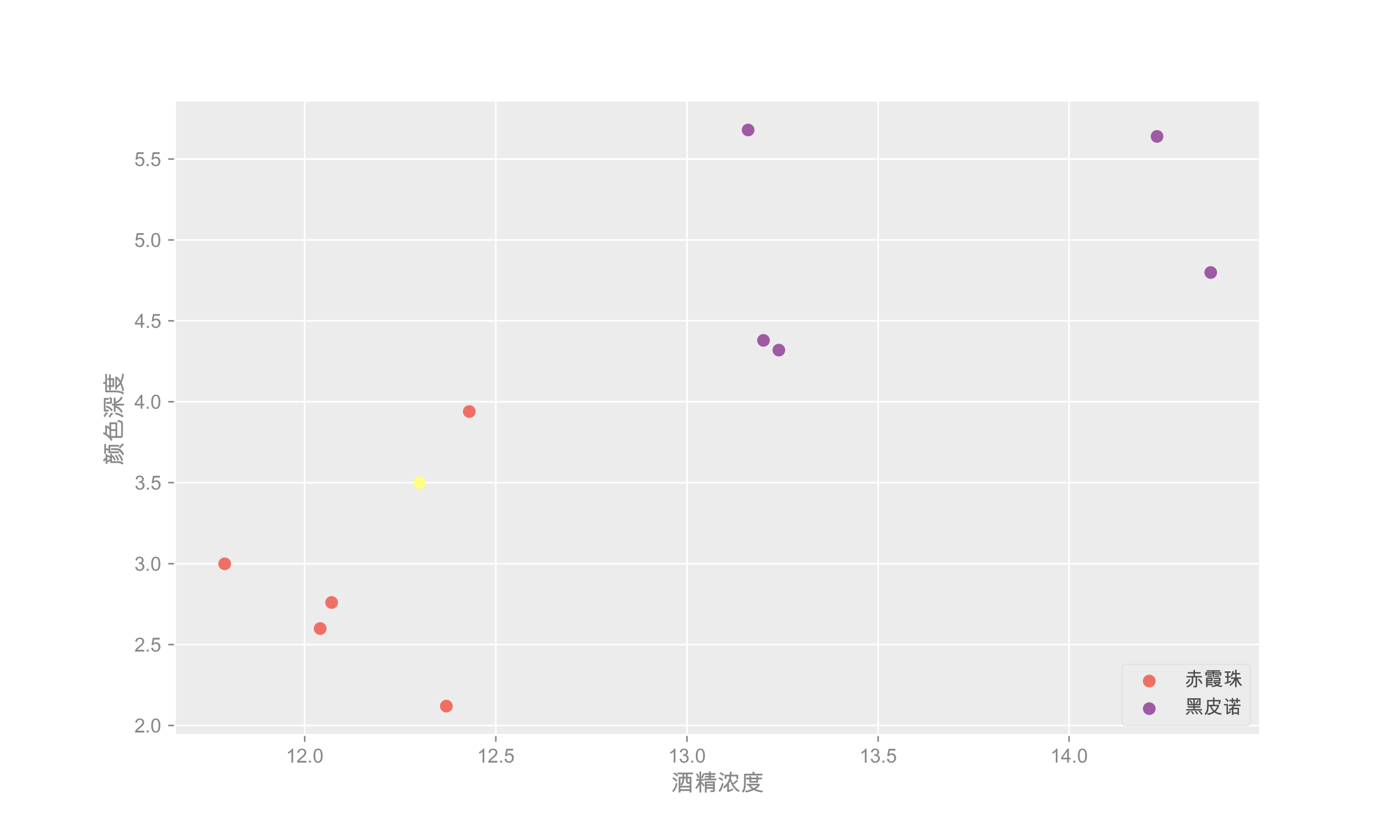
可以很明显的看出:赤霞珠和黑皮诺在空间当中,分布的范围有明显的区别。那么我们要如何对这杯新酒的类别进行预测呢?
当然是找出它和哪些类别的酒在空间中更接近一些。
此时就需要借助KNN算法工具。
(3)KNN算法分类识别:
在本例中,离黄色点最近的3个点都是红色点,所以红点和紫色类别的投票数是3:0,红色取胜,所以黄色点属于红色,也就是新的一杯属于「赤霞珠」。
这样一来,对于这杯新的红酒的分类就完成啦,这也就是KNN算法执行的流程,是不是非常简单呢?
 findNaN.py
Ipython Shell
findNaN.py
Ipython Shell
